Quindi, buttiamo tutto sulla matrice, e vediamo che possono esserci abitanti stanziali connessi e non connessi, oppure abitanti nomadi, a loro volta connessi o meno.
Quindi, buttiamo tutto sulla matrice, e vediamo che possono esserci abitanti stanziali connessi e non connessi, oppure abitanti nomadi, a loro volta connessi o meno.
Tenete sempre presente che parliamo di abitare Luoghi indifferentemente dentro o fuori il web, digitali o fisici. E anche su web è possibile ravvisare comportamenti stanziali o nomadi, da parte di singoli, gruppi e collettività più ampie. Ti piace cliccare sui blogroll altrui, verso l’Ignoto? O sui followers di Tizio? Nomadizzi, t’incuriosisci per un nick e segui briciole di pane o suggestive scie di profumo per mezza Internet, ti impelaghi. Perché ricordate, il web era un mare da navigare e surfare, e di qua e di là qualche isoletta offriva approdo.
Il web non è più un posto per scorrerie, qui noi oggi abitiamo. Abbiamo fatto terra-forming per dieci anni, adesso mettiamo i piedi su cose solide e di noi stabilmente identitariamente connotate, come il nostro blog che ci guarda da qualche anno o il forum che frequento da quando cercavo gli aggiornamenti per windows98 o le reti dei messenger.
Qui ora vado in direzione degli eventi che con maggiore probabilità possono innescare cambiamenti sociali: ad esempio, in collettività umane attraversate dal flusso nomadico degli zingari credo si formino credenze riguardo alla relazione con l’Altro diverse rispetto a raggruppamenti sociali stabili che conoscono pochi contatti con lo Straniero.
Quindi il tutto si riverbera nel web, dove molti di noi stanziali connessi adottiamo comportamenti che talvolta rafforzano la relazione dentro le reti conosciute, dentro l’insieme olistico dei Luoghi che frequento e quelli fino dove giungono le mie tracce di presenza, e talvolta, restando stanziali, diventiamo veri nomadi, nel muoverci su territori digitali sconosciuti.
Nel corso del tempo è cambiato il nostro propendere per “rafforzamento rete sociale conosciuta” rispetto a “esplorazione reti sconosciute”? Reti di persone, di socialità. Una volta si aggregavano di più le cose, oggi si aggregano le persone? Tutti i socialweb che articolano il concetto di follower, che lo visualizzano, che mettono in scena le reti contribuiscono a “stringere” le reti? E quanto incoraggiano il nomadismo, come apertura allo stupore dell’epifania numinosa quanto inattesa dell’Altro da me, eh?, nei percorsi serendipici?
Conservatori o progressisti? No, prima ancora. Disposti a porgere l’orecchio e l’occhio e la freccina del mouse a un link ipertestuale che vi porterà chissà dove, a leggere di argomenti o vedere foto di cose prima mai pensate, oppure a lasciar entrare nel vostro aggregatore e nella vostra coscienza flussi di alterità, questo scegliamo per noi stessi, così impostiamo i filtri del lifestreaming da e verso di noi, così costruiamo e usiamo le porte e i segni.
Cosa cerco dalla conoscenza? Conferme o sgambetti?
Nel MedioEvo, la comunicazione pubblica delle PA (i feudatari) era zero, a parte le grida in pubblica piazza e quell’albo pretorio che ha millenni di storia. Conservare il potere (basato sulle informazioni, poi) era ed è non comunicare. E’ chiaro che esporsi alla comunicazione è esporsi al cambiamento, e qualcuno giunge ad affermare che negarsi alla comunicazione è negare il cambiamento, ovvero il volersi mantenere uguali, conservare l’attuale.
Anche se vedo contradittoria una società che si vuole progressista che sbarra le porte (la Cina?).
Qui c’è Massimo Moruzzi su Dotcoma che vede bene lo stesso problema, riferendosi a come i contenitori sociali su web e i loro meccanismi pre-orientino la relazione e in-formino il nostro abitare nelle reti.
Facebook, vale la pena a questo punto sottolineare, non è più un sistema chiuso su sé stesso – o non più di quanto non lo siano il tuo feedreader o la tua webmail, perchè vi puoi importare praticamente di tutto, come e più che su un feedreader, o ricevere di tutto, come con la tua email.
Facebook ha vinto, ma senza risolvere nulla. Su Facebook, vedo foto, link, video e musica dei miei amici – ma non sarebbe molto più interessante vedere cosa apprezza chi ha gusti simili ai miei? Facebook è un passo indietro da un web di interessi condivisi a un web di amici che già conosci.
Questo accade perché proprio questa è la peculiarità del social web, lo dice la parola stessa. Permettendo l’emergere e quindi la visibilità delle reti relazionali, ha posto l’attenzione sulle persone. L’altro ieri andavo su web per cercare un documento o una risorsa, ieri per cercare delle persone, oggi cerco cosa dicono le persone che stimo e/o conosco sulle risorse e sulle novità, domani saremo tutti presi in un vortice vorticoso di cose e oggetti geotaggati e news e commenti e lifestreaming.
Il “web degli amici che già conosci” è una fase necessaria di ristrutturazione dell’economia della rete, perché permette di organizzare meglio i filtri e le reti dei flussi di informazioni e opinioni sulle informazioni, in direzione di una maggior efficacia nella propagazione delle idee, nel web degli interessi condivisi.
Si guardavano gli oggetti culturali, ora si guardano le persone, ma si tornerà a guardare gli oggetti, però incomparabilmente arricchiti dalle riflessioni di molti su di essi, da prezioso contesto, da vissuto personale.
Dopo questa costrizione che il socialweb ha imposto al nostro fare negli ultimi anni, nel farci concentrare sulla edificazione dei Luoghi sociali del nostro abitare, sull’allestimento di una identità adeguata ai nuovi ambienti che frequento, sulla definizione di una rete amicale e professionale, possiamo tornare a estrovertirci, verso cose che non conosco.
Un altro esempio: la funzione dei commenti dentro Google Reader. C’è questa funzione nuova per commentare ed inoltrare ad altri quello che ci arriva dentro l’aggregatore e reputiamo meritevole di.
C’è la condivisione “Share with note”, che rimanda la notizia ai vostri amici (chi già riceve ciò che segnalate), e il commento e la notizia possono anche essere pubblicati sulla pagina pubblica del mio aggregatore.
Ma da poco tempo anche dentro il bottone “Share”, quello per la semplice condivisione con un click, troviamo una ulteriore funzione di commento, dove però la visibilità dello stesso è rivolta “a tutti quelli che possono vedere la notizia originale condivisa”.
Che quindi potrebbero essere anche persone che non sono vostre amiche (ovvero nel vostro elenco di persone con cui condividete permanentemente il flusso di pubblicazione), ma in qualche modo la stessa notizia è presente anche nel loro aggregatore e se leggeranno la notizia dopo di voi vedranno anche il vostro eventuale commento. Immagino.
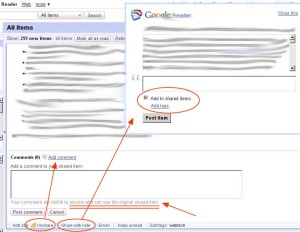
Quindi, nel primo caso ho condivisione e aumento informativo (il mio commento) verso reti conosciute, nel secondo caso compio un movimento molto più “alla cieca”, senza finalità immediate, ma potenzialmente foriero di inaspettato, cose o persone si tratti.
Dove decido di interfacciarmi? Nello scegliere attimo per attimo come utilizzare e come reinoltrare risorse, persone, memi, nel mio essere router di socialità, mi rivolgo a reti conosciute o sconosciute? Nel pensare il destino del mio dire e del mio fare in rete, mi viene più facile immaginare uno sconosciuto o un amico, nell’attimo di leggere l’ultimo post del mio blog sul suo aggregatore? E quanta fiducia ci metto, nell’inoltrare (e questo torna ad assomigliare a un messaggio nella bottiglia in un web che torna ad essere un po’ mare) e nell’ascoltare?
ps. dopo geni e memi, ci servirebbe una unità di significato delle reti sociali, dei cluster relazionali, dove il contenuto è dato dalla forma peculiare che ciascun sistema adotta.